
Database Design & Modeling:
Designed a normalized relational database schema with multiple interconnected tables.
Ensured the database adhered to best practices like normalization (up to 3NF) to reduce redundancy and improve efficiency.
Entity-Relationship (ER) Modeling:
Developed an ER diagram to visually represent the structure and relationships between different entities (Books, Members, Employees, Branches, etc.).
Used foreign keys to ensure referential integrity and maintain consistent data across the tables.
Data Integrity & Constraints:
Implemented primary and foreign keys, not null, unique, and default constraints to ensure data accuracy and prevent errors.
Focused on data validation and integrity to prevent invalid or incomplete data entry.
Database Visualization & Tools:
Utilized MySQL Workbench or similar database management tools to visually design and manage the database schema.
Familiarity with the UI/UX of database management software for efficient and intuitive database management.
Scalability & Optimization:
Designed the schema with future scalability in mind, enabling the addition of more tables or data without breaking the structure.
Focused on making the database easy to query for both small and large datasets, ensuring smooth performance.
Problem-Solving & Requirements Analysis:
Translated real-world library management requirements into a structured database design.
Identified key entities and relationships (such as issued books, return status, member details) and organized them effectively.
This project involved designing a database schema for a library management system. The system needed to handle various tasks such as tracking books, employees, library branches, members, and the status of books that were issued and returned.
I created a relational database, ensuring the schema was normalized to minimize redundancy and improve data integrity. The schema consists of multiple tables, each with its own specific attributes and relationships:
Books Table – Stores details about books, including ISBN, title, category, and publisher.
Employees Table – Contains information about library employees, such as their ID, name, position, and branch.
Members Table – Manages member details like ID, name, address, and registration date.
Branches Table – Keeps track of library branches, including their address and branch manager.
Issued_Status Table – Monitors the books that have been issued, linking books, members, and employees, with an issue date.
Return_Status Table – Tracks the return of books, including the return date and related issues.
Relationships were established using foreign keys to ensure referential integrity between tables. I focused on ensuring the database could easily scale, allowing for efficient querying of data such as overdue books, member history, or employee activities.
I also set up necessary constraints like primary keys, unique keys, and not-null constraints, ensuring that data was accurate and consistent. I visualized the database schema and implemented it, making the design easy to manage and understand.
This project demonstrates my ability to design complex database systems, manage relationships between entities, and ensure data integrity within a real-world application.
In this first step, the primary focus is on designing the foundational structure of the database, which includes creating the core tables that will store the essential data for the library management system. At this point, the schema is organized but does not yet establish the relationships or foreign key constraints between the tables.
The key entities in this step are:
Books Table: This table is designed to hold all the essential details about each book in the library’s collection. This includes the book’s unique identifier, title, category, rental price, and its current status (whether available or checked out). Additionally, it stores information about the book’s publisher, which will help in categorizing and managing the library’s collection.
Employees Table: The employee table is built to track library staff. This includes storing employee identification details, names, positions, and salaries. It also contains information about the branch to which each employee is assigned. At this point, the connection to the branch table is identified, but no foreign key relationships have yet been set up.
Branch Table: This table stores information regarding each library branch. It includes details such as the branch’s unique identifier, the manager in charge, the branch’s address, and its contact information. While the schema is laid out, the connection between the branch and other entities, like employees or members, has yet to be established through foreign keys.
Members Table: The members table is meant to store all the necessary information about library members, such as their unique membership ID, name, address, and the date they registered. The table is structured but does not yet have any links to issued books or return status.
Issued_Status Table: This table will eventually track which books are issued to which members. It is designed to store information about issued books, such as the member ID and the date the book was issued. However, in this initial design step, no explicit relationship between members and books is defined yet.
Return_Status Table: The return status table is created to manage the return process of borrowed books. It is intended to track when books are returned and whether there are any conditions related to the book upon return. Similar to the Issued_Status table, the connections to the relevant entities (books and members) are planned but not yet formalized with foreign keys.
Structural Foundation: At this stage, the goal is to establish a clear and consistent layout for the database, focusing on defining the core entities and their attributes. Each table has been designed to store relevant data for the library management system, but the relationships between these tables have not yet been introduced.
Data Types and Storage: The tables are structured with appropriate data types, ensuring each attribute can store the necessary information. This includes text-based fields for names, addresses, and titles, as well as numeric fields for things like employee salaries and book rental prices. Temporal data types are also included to handle issue and return dates.
Focus on Individual Entities: No relationships have been established between tables yet. Each table is independent at this stage, and the focus is purely on the layout and structure of the data. This modular design will be further enhanced in the next steps when foreign keys and relationships between entities are introduced.
Foundation for Future Steps: The primary objective of this step is to create a database schema that will serve as the basis for future development. Once the structure is in place, the next steps will involve linking these tables through foreign keys and ensuring data integrity, which will enable the system to function efficiently.
This initial setup provides the groundwork for building a relational database that can manage the various operations of the library system, including tracking books, employees, branches, members, and the status of borrowed and returned books.
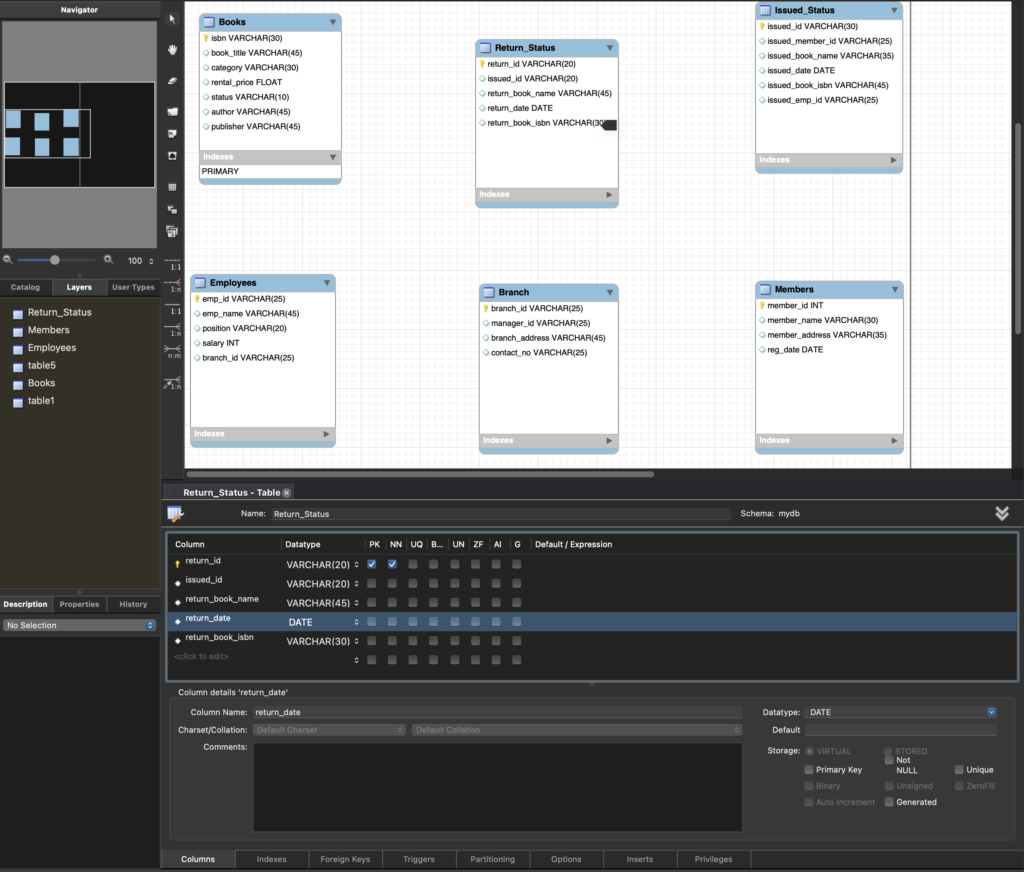
In this step, the database schema transitions from a simple, isolated table structure to a fully relational model. The entities from Step 1 are now connected through foreign key relationships, ensuring data integrity and establishing the logical links between them. This setup enables more advanced operations, such as querying related data across multiple tables, ensuring that the database can handle the operations of a library management system efficiently.
Key updates in this step:
Books and Issued_Status Relationship: The Books table is now linked to the Issued_Status table via the issued_book_isbn column. This relationship ensures that each record in Issued_Status corresponds to a specific book from the Books table, allowing the system to track which books are currently issued.
Issued_Status and Members Relationship: The Issued_Status table is now associated with the Members table through the issued_member_id field. This foreign key links each issued book to a specific library member, ensuring that the system can track who has borrowed which book.
Issued_Status and Employees Relationship: The Issued_Status table is also connected to the Employees table via the issued_emp_id field. This establishes a link between the books being issued and the library employees who handled the issuance, allowing for employee tracking.
Return_Status and Issued_Status Relationship: The Return_Status table is now linked to the Issued_Status table using the issued_id field. This relationship ensures that every return entry corresponds to an issued book, enabling the system to track the return status of each issued book.
Members and Branch Relationship: The Members table is connected to the Branch table via the branch_id field. This relationship ensures that each member is associated with a specific library branch, allowing the system to track which branch a member belongs to.
Employees and Branch Relationship: The Employees table is now related to the Branch table through the branch_id field. This link ties each employee to a specific library branch, enabling the system to determine where each employee works.
Foreign Keys Introduced: This step introduces foreign keys to establish connections between related entities. For example, linking members to issued books and employees to branches ensures the relational integrity of the database. Foreign keys also enforce constraints that prevent orphaned records (i.e., records that reference non-existent data).
Enabling Relational Queries: With these relationships in place, the database can now handle relational queries more effectively. For example, it’s possible to query all books issued by a particular member or all books returned by a specific employee. The relationships set up in this step enable these more complex queries.
Enhanced Data Integrity: By establishing these relationships, the database design ensures data consistency. For instance, when a book is issued, it must reference an existing member and employee, preventing the creation of invalid records.
Improved Structure for Scalability: The relational structure set up in this step ensures that the system is scalable, making it easier to manage large datasets as the library grows. It provides a more efficient way to link and retrieve data across multiple tables as the system evolves.
This step sets the foundation for an operational system that can track books, members, employees, and their interactions efficiently.
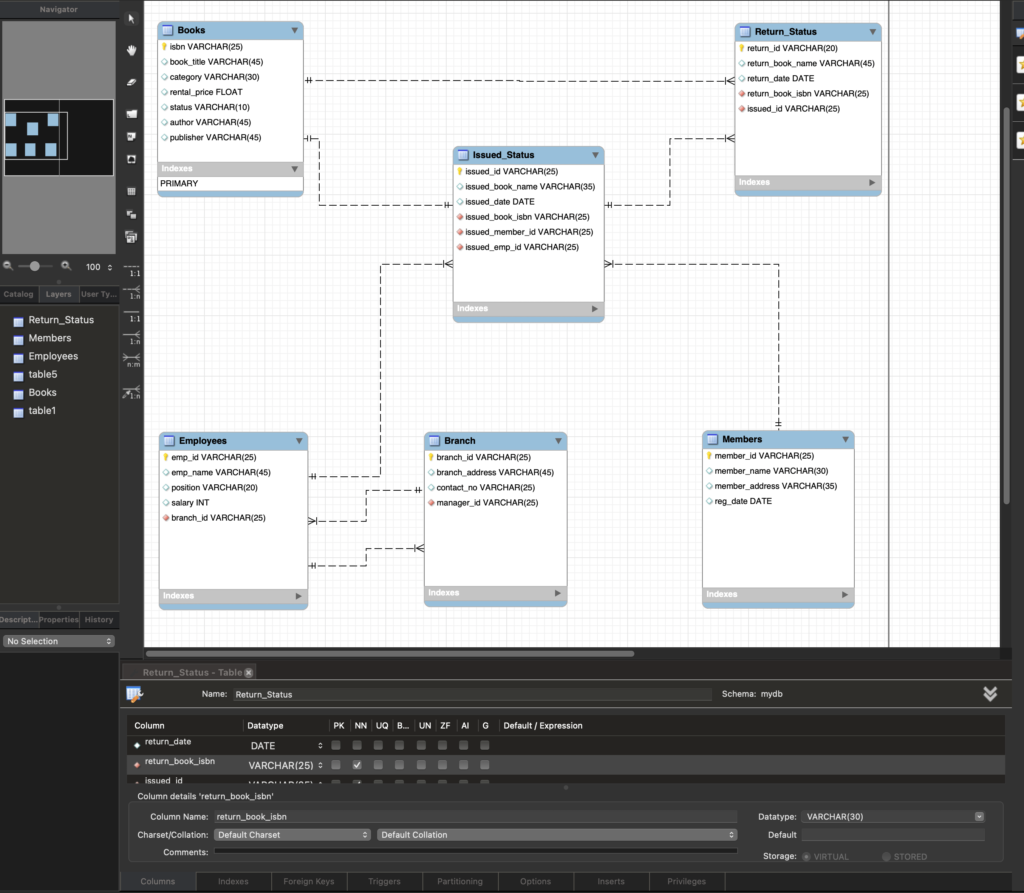
In this step, the database schema that has been designed and refined in previous steps is now ready to be implemented in the MySQL database. Using the forward engineering tool, we can generate the necessary SQL scripts to create the tables, relationships, and constraints in the actual database.
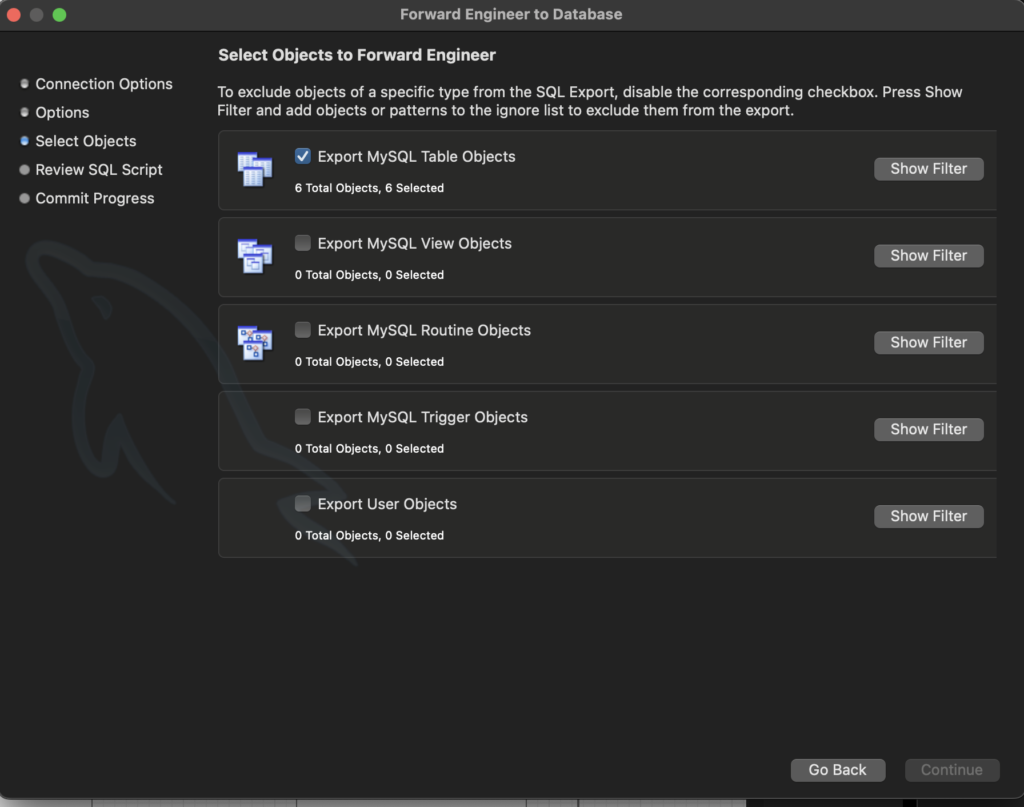
Here, the focus is on exporting the MySQL Table Objects for the database schema. This step ensures that the tables, along with their structures and attributes, are generated based on the design created in the previous steps. By selecting the option to export MySQL Table Objects, the system prepares to create the SQL commands that will create each table with the defined columns, data types, and constraints.
The export process ensures that all tables from the schema—Books, Employees, Branches, Members, Issued_Status, and Return_Status—are included in the SQL script, making it possible to apply the schema to the database. At this point, we are not yet focusing on views, triggers, or user-defined objects, so those are left unselected.
Table Objects Export: Only table objects are selected for export. This step focuses on creating the actual tables with all defined columns, primary keys, and constraints.
SQL Script Generation: The tool prepares an SQL script based on the schema, which will be used to create the database tables and relationships.
No Other Objects: We leave out exporting views, routines, triggers, or user objects for now since the focus is on the database’s table structure.
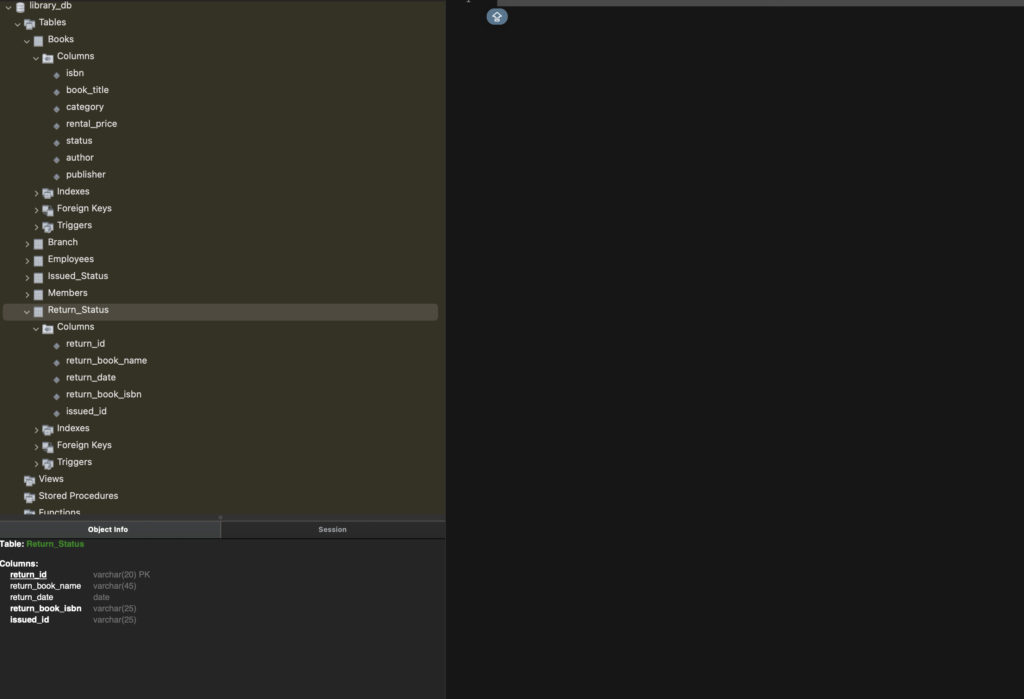
After reviewing and confirming the SQL script, the next step is to execute the script. This will apply all the changes, creating the tables, relationships, and constraints as per the design. The execution process involves running the SQL script, which will create the actual database schema in the system.
Key actions in this step include:
Running the SQL Script: Execute the script that generates the tables and establishes the relationships between them.
Validation: Ensure that the database objects (tables, foreign keys, indexes, etc.) are successfully created without errors.
Error Handling: If any errors occur during execution, these need to be addressed (e.g., checking for missing data types or constraint violations).
This step is crucial because it transforms the conceptual database schema into a working, operational database. Once the script is executed successfully, the database is ready to store, retrieve, and manage data based on the structure defined in the previous steps.
After successfully executing the SQL script, the next step is testing the newly created database schema to ensure that it works as expected. This includes verifying that:
Tables are created: All the tables, including their columns, data types, and constraints, should be present in the database.
Relationships are intact: The foreign keys and relationships between tables should function properly, ensuring that referential integrity is maintained.
In this project, I designed and implemented a relational database schema for a library management system, following a clear, step-by-step approach to ensure everything was organized and functional.
Database Schema Design: I started by designing the core tables for the library system, including Books, Employees, Branches, Members, Issued_Status, and Return_Status. Each table was created with the necessary attributes to store all the relevant data for the system.
Establishing Relationships: Once the tables were set up, I established relationships between them using foreign keys. This ensured data integrity and allowed the tables to be properly linked, so I could track which books were issued, by whom, and when they were returned.
Forward Engineering the Database: After the schema was finalized, I used the forward engineering tool to generate an SQL script that would create the database tables and their relationships. I exported only the MySQL Table Objects to ensure that only the tables I needed were included in the export.
Reviewing the SQL Script: Before executing the SQL script, I thoroughly reviewed it to ensure it accurately reflected the database design. This was a crucial step to make sure there were no mistakes or omissions.
Executing the SQL Script: After confirming that everything was correct, I ran the SQL script to create the tables and relationships in the database. This step turned the conceptual schema into an actual working database.
Testing the Database: After executing the script, I tested the database by inserting sample data and running queries to make sure everything was functioning as expected. This involved checking that the relationships worked properly, and that data integrity was maintained when inserting, updating, and deleting records.
By completing these steps, I successfully created a well-structured relational database for the library management system. This process helped me understand the importance of relational integrity, normalization, and efficient database design. The final product is a functional system that can be scaled and extended with additional features as needed.
Emmanuel Olorunda
Copyright © 2025 | All Rights Reserved
Every project starts with a chat, Emmanuel is keen to conversation and open to discussing your project. he will pull in the right expertise when needed